
Kubernetes 基础架构
Kubernetes 基础架构

Master & Node
Master
master为集群的控制节点,master 负责集群中的全局决策(例如,调度),master 探测并响应集群事件(例如,当 Deployment 的实际 Pod 副本数未达到 replicas 字段的规定时,启动一个新的 Pod)
master节点通常包含:kube-apiserver、Etcd、Controller Manager、Scheduler组件
kube-apiserver
Kubernetes API Server的核心功能是提供Kubernetes各类资源对象(如Pod、 RC、 Service等) 的增、 删、 改、 查及Watch等HTTP Rest接口, 成为集群内各个功能模块之间数据交互和通信的中心枢纽,是整个系统的数据总线和数据中心。 除此之外它还是:集群管理的API入口 、资源配额控制的入口 、为集群提供了完备的集群安全机制。
在默认情况下, kube-apiserver进程在本机的8080端口(对应参数–insecure-port) 提供REST服务。 我们可以同时启动HTTPS安全端口(–secure-port=6443) 来启动安全机制, 加强REST API访问的安全性。 通常可以通过命令行工具kubectl来与Kubernetes API Server交互, 它们之间的接口是RESTful API。
Kubernetes API Server 创建Pod过程借助自身的List-Watch机制: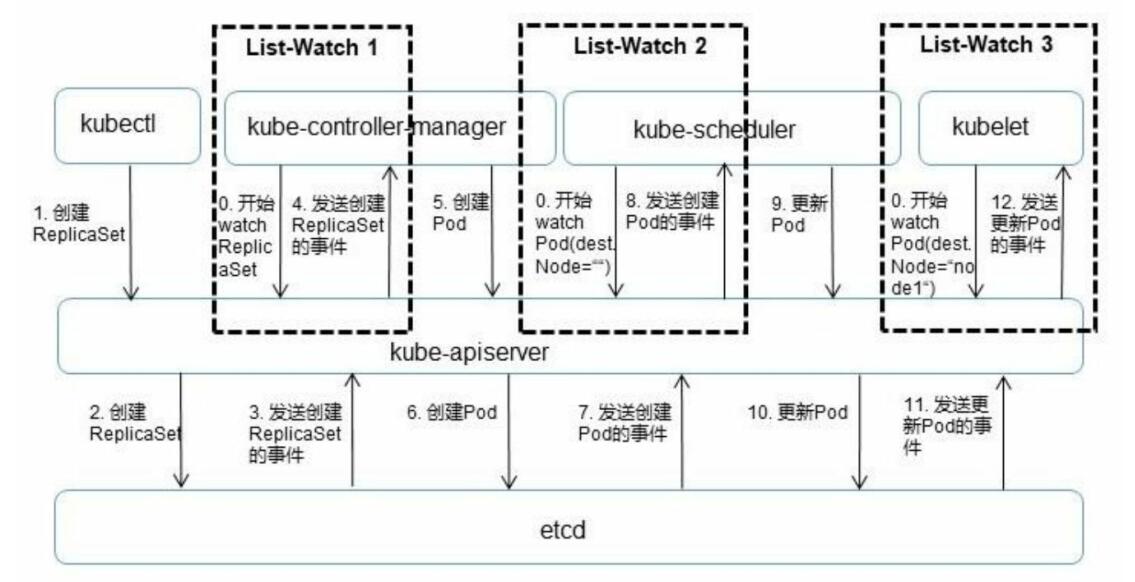
etcd
etcd 是一个分布式的、可靠的 key-value 存储系统,它用于存储分布式系统中的关键数据
一个 etcd 集群,通常会由 3 个或者 5 个节点组成,多个节点之间,通过一个叫做 Raft 一致性算法的方式完成分布式一致性协同,算法会选举出一个主节点作为 leader,由 leader 负责数据的同步与数据的分发,当 leader 出现故障后,系统会自动地选取另一个节点成为 leader,并重新完成数据的同步与分发。客户端在众多的 leader 中,仅需要选择其中的一个就可以完成数据的读写。
在 etcd 整个的架构中,有一个非常关键的概念叫做 quorum,quorum 的定义是 =(n+1)/2,也就是说超过集群中半数节点组成的一个团体,在 3 个节点的集群中,etcd 可以容许 1 个节点故障,也就是只要有任何 2 个节点重合,etcd 就可以继续提供服务。同理,在 5 个节点的集群中,只要有任何 3 个节点重合,etcd 就可以继续提供服务。这也是 etcd 集群高可用的关键。
我们可以通过 etcd 提供的客户端去访问集群的数据,也可以直接通过 http 的方式,类似像 curl 命令直接访问 etcd。在 etcd 内部,其数据表示也是比较简单的,我们可以直接把 etcd 的数据存储理解为一个有序的 map,它存储着 key-value 数据。同时 etcd 为了方便客户端去订阅资料的数据,也支持了一个 watch 机制,我们可以通过 watch 实时地拿到 etcd 中数据的增量更新,从而保持与 etcd 中的数据同步。
etcd 的数据版本号机制:
- etcd 中有个 term 的概念,代表的是整个集群 Leader 的标志。当集群发生 Leader 切换,比如说 Leader 节点故障,或者说 Leader 节点网络出现问题,再或者是将整个集群停止后再次拉起,这个时候都会发生 Leader 的切换。当 Leader 切换的时候,term 的值就会 +1
- revision 代表的是全局数据的版本。当数据发生变更,包括创建、修改、删除,revision 对应的都会 +1。在任期内,revision 都可以保持全局单调递增的更改。正是 revision 的存在才使得 etcd 既可以支持数据的 MVCC,也可以支持数据的 Watch
- 对于每一个 KeyValue 数据,etcd 中都记录了三个版本:
- 第一个版本叫做 create_revision,是 KeyValue 在创建的时候生成的版本号;
- 第二个叫做 mod_revision,是其数据被操作的时候对应的版本号;
- 第三个 version 就是一个计数器,代表了 KeyValue 被修改了多少次。
在 watch 的时候指定数据的版本,创建一个 watcher,并通过这个 watcher 提供的一个数据管道,能够获取到指定的 revision 之后所有的数据变更。如果指定的 revision 是一个旧版本,可以立即拿到从旧版本到当前版本所有的数据更新。并且,watch 的机制会保证 etcd 中,该 Key 的数据发生后续的修改后,依然可以从这个数据管道中拿到数据增量的更新。
在 etcd 中会周期性的运行一个 Compaction 的机制来清理历史数据。对于一个 Key 的历史版本数据,可以选择清理掉。
lease 是分布式系统中一个常见的概念,用于代表一个租约。通常情况下,在分布式系统中需要去检测一个节点是否存活的时候,就需要租约机制。当租约过期时,etcd 就会自动清理掉对应的数据。也可以使用调用 KeepAlive 的方法,与 etcd 保持一个租约不断的续约
Etcd写数据流程
- etcd 任一节点的 etcd server 模块收到 Client 写请求(如果是 follower 节点,会先通过 Raft 模块将请求转发至 leader 节点处理)。
- etcd server 将请求封装为 Raft 请求,然后提交给 Raft 模块处理。
leader 通过 Raft 协议与集群中 follower 节点进行交互,将消息复制到follower 节点,于此同时,并行将日志持久化到 WAL。 - follower 节点对该请求进行响应,回复自己是否同意该请求。
- 当集群中超过半数节点((n/2)+1 members )同意接收这条日志数据时,表示该请求可以被Commit,Raft 模块通知 etcd server 该日志数据已经 Commit,可以进行 Apply。
- 各个节点的 etcd server 的 applierV3 模块异步进行 Apply 操作,并通过 MVCC 模块写入后端存储 BoltDB。
- 当 client 所连接的节点数据 apply 成功后,会返回给客户端 apply 的结果。
Etcd读数据流程
- etcd 任一节点的 etcd server 模块收到客户端读请求(Range 请求)
- 判断读请求类型,如果是串行化读(serializable)则直接进入 Apply 流程
- 如果是线性一致性读(linearizable),则进入 Raft 模块
- Raft 模块向 leader 发出 ReadIndex 请求,获取当前集群已经提交的最新数据 Index
- 等待本地 AppliedIndex 大于或等于 ReadIndex 获取的 CommittedIndex 时,进入 Apply 流程
- Apply 流程:通过 Key 名从 KV Index 模块获取 Key 最新的 Revision,再通过 Revision 从 BoltDB 获取对应的 Key 和 Value。
Controller Manager
Controller Manager是Kubernetes中各种操作系统的管理者, 是集群内部的管理控制中心, 也是Kubernetes自动化功能的核心
Controller Manager内部包含Replication Controller、Node Controller、 ResourceQuota Controller、Namespace Controller、ServiceAccount Controller、 Token Controller、 Service Controller及Endpoint Controller这8种Controller, 每种Controller都负责一种特定资源的控制流程, 而Controller Manager正是这些Controller的核心管理者。 Controller 保证集群内的资源保持预期状态,而 Controller Manager 保证了 Controller 保持在预期状态。
Controller Manager的工作流程:
从比较高维度的视角看,Controller Manager 主要提供了一个分发事件的能力,而不同的 Controller 只需要注册对应的 Handler 来等待接收和处理事件。
Controller Manager的架构:
Controller 是下半部分(CustomController)描述的内容,而 Controller Manager 主要完成的是上半部分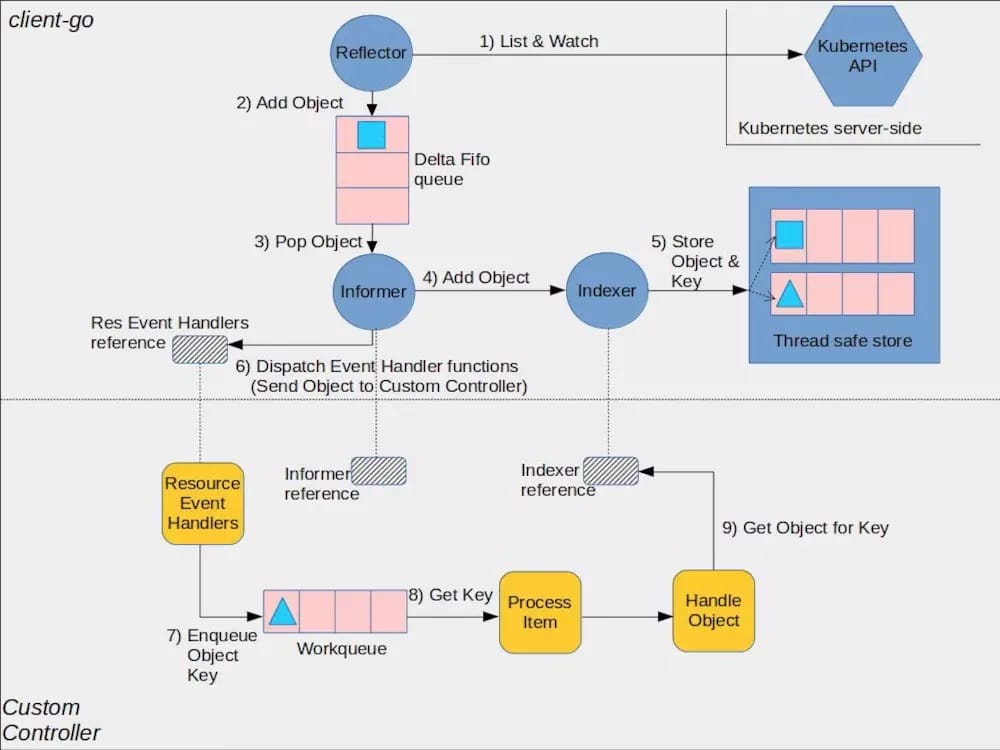
- Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod
- Reflect 拿到全部 Pod 后,会将全部 Pod 放到 Store 中
- 如果有人调用 Lister 的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据
- Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件;如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件
- Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO
- DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1
- DeltaFIFO 再 Pop 这个事件到 Controller 中
- Controller 收到这个事件,会触发 Processor 的回调函数
Etcd存储集群的数据信息,apiserver作为统一入口,任何对数据的操作都必须经过 apiserver。客户端(kubelet/scheduler/controller-manager)通过 list-watch 监听 apiserver 中资源(pod/rs/rc等等)的 create, update 和 delete 事件,并针对事件类型调用相应的事件处理函数。
那么list-watch 具体是什么呢,顾名思义,list-watch有两部分组成,分别是list和 watch。list 非常好理解,就是调用资源的list API罗列资源,基于HTTP短链接实现;watch则是调用资源的watch API监听资源变更事件,基于HTTP 长链接实现。
Informer是 Client-go中的一个核心工具包。K8S 的informer 模块封装 list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc, UpdateFunc和 DeleteFunc等。如下图所示,informer首先通过list API 罗列资源,然后调用 watch API监听资源的变更事件,并将结果放入到一个 FIFO 队列,队列的另一头有协程从中取出事件,并调用对应的注册函数处理事件。Informer还维护了一个只读的Map Store 缓存,主要为了提升查询的效率,降低apiserver 的负载。
Scheduler
Kubernetes Scheduler的作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建Pod等)按照特定的调度算法和调度策略绑定(Binding)到集群中某个合适的Node上,并将绑定信息写入etcd中。在整个调度过程中涉及三个对象,分别是待调度Pod列表、可用Node列表,以及调度算法和策略。简单地说,就是通过调度算法调度为待调度Pod列表中的每个Pod从Node列表中选择一个最适合的Node。
Kubernetes Scheduler当前提供的默认调度流程分为以下两步:
- 预选调度过程,即遍历所有目标Node,筛选出符合要求的候选节点。为此,Kubernetes内置了多种预选策略(xxx Predicates)供用户选择。
- 确定最优节点,在第1步的基础上,采用优选策略(xxxPriority)计算出每个候选节点的积分,积分最高者胜出。

- 调度器启动时会通过配置文件 File,或者是命令行参数,或者是配置好的 ConfigMap,来指定调度策略
- 启动的时候会通过 kube-apiserver 去 watch 相关的数据,通过 Informer 机制将调度需要的数据
- 通过 Informer 去 watch 到需要等待的 Pod 数据,放到队列里面,通过调度算法流程里面,会一直循环从队列里面拿数据,然后经过调度流水线(调度器的调度流程 –》Wait 流程 –》Bind 流程)
- 调度完成后,会去更新调度缓存 (Schedule Cache),如更新 Pod 数据的缓存,也会更新 Node 数据
具体可见图
Node
Node是Kubernetes中的工作节点,最开始被称为minion。一个Node可以是VM或物理机。每个Node(节点)具有运行pod的一些必要服务,并由Master组件进行管理,Node节点上的服务包括Docker、kubelet和kube-proxy。
Kubelet
在Kubernetes集群中,在每个Node(又称Minion)上都会启动一个kubelet服务进程。该进程用于处理Master下发到本节点的任务,管理Pod及Pod中的容器。每个kubelet进程都会在API Server上注册节点自身的信息,定期向Master汇报节点资源的使用情况,并通过cAdvisor监控容器和节点资源。
kubelet详细架构解析
Kubelet组件运行在Node节点上,维持运行中的Pods以及提供kuberntes运行时环境,主要完成以下使命
- 监视分配给该Node节点的pods
- 挂载pod所需要的volumes
- 下载pod的secret
- 通过docker/rkt来运行pod中的容器
- 周期的执行pod中为容器定义的liveness探针
- 上报pod的状态给系统的其他组件
- 上报Node的状态
LivenessProbe探针
LivenessProbe探针,用于判断容器是否健康并反馈给kubelet。如果LivenessProbe探针探测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success.
kubelet定期调用容器中的LivenessProbe探针来诊断容器的健康状况。LivenessProbe包含以下3种实现方式
- ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果端口能被访问,则表明容器健康。
- HTTPGetAction:通过容器的IP地址和端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于等于400,则认为容器状态健康。
ReadinessProbe探针
ReadinessProbe探针,用于判断容器是否启动完成,且准备接收请求。如果ReadinessProbe探针检测到容器启动失败,则Pod的状态将被修改,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目.
kubelet命令技巧
获取所有未运行的 Pod(即状态不为 Running 的):
kubectl get pods -A –field-selector=status.phase!=Running | grep -v Complete
获取节点列表及其内存大小:
kubectl get no -o json | jq -r ‘.items | sort_by(.status.capacity.memory)[] | [.metadata.name,.status.capacity.memory] | @tsv’
获取节点列表和在其上运行的容器的数量:
kubectl get po -o json –all-namespaces | jq ‘.items | group_by(.spec.nodeName) | map({“nodeName”: .[0].spec.nodeName, “count”: length}) | sort_by(.count)’
用 kubectl top 获取消耗CPU的Pod列表:
kubectl top pods -A | sort –reverse –key 3 –numeric
用 kubectl top 获取消耗内存资源的Pod列表:
kubectl top pods -A | sort –reverse –key 4 –numeric
将 secret 从一个命名空间复制到另一命名空间空间:
kubectl get secrets harbor -o json –namespace demo | jq ‘.metadata.namespace = “default”‘ | kubectl create -f -
Kube-proxy
在Kubernetes集群的每个Node上都会运行一个kube-proxy服务进程,我们可以把这个进程看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。此外,Service的Cluster IP与NodePort等概念是kube-proxy服务通过iptables的NAT转换实现的,kube-proxy在运行过程中动态创建与Service相关的iptables规则,这些规则实现了将访问服务(Cluster IP或NodePort)的请求负载分发到后端Pod的功能。先后经过三代变更,目前采用的是IPVS。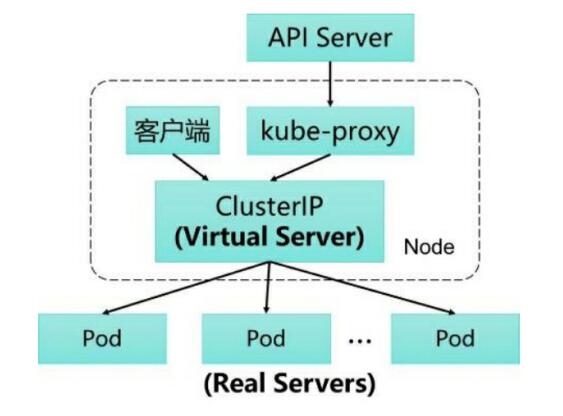
通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息, 并更新对应的iptables规则, Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
与iptables相比, IPVS拥有以下明显优势:
- 为大型集群提供了更好的可扩展性和性能
- 支持比iptables更复杂的复制均衡算法( 最小负载、 最少连接、加权等)
- 支持服务器健康检查和连接重试等功能
- 可以动态修改ipset的集合, 即使iptables的规则正在使用这个集合
由于IPVS无法提供包过滤、 airpin-masquerade tricks(地址伪装) 、SNAT等功能, 因此在某些场景(如NodePort的实现) 下还要与iptables搭配使用。
主要的iptables规则
- KUBE-CLUSTER-IP: 在masquerade-all=true或clusterCIDR指定的情况下对Service Cluster IP地址进行伪装, 以解决数据包欺骗问题 。
- KUBE-EXTERNAL-IP: 将数据包伪装成Service的外部IP地址。
- KUBE-LOAD-BALANCER、 KUBE-LOAD-BALANCERLOCAL: 伪装Load Balancer 类型的Service流量。
- KUBE-NODE-PORT-TCP、 KUBE-NODE-PORT-LOCALTCP、 KUBE-NODE-PORTUDP、 KUBE-NODE-PORT-LOCAL-UDP:伪装NodePort类型的Service流量。
Container Runtime
容器运行时接口(Container Runtime Interface) CRI,定义了一组 gRPC 接口:
- 一套针对容器操作的接口,包括创建,启停容器等等
- 一套针对镜像操作的接口,包括拉取镜像删除镜像等;
- 还有一套针对 PodSandbox(容器沙箱环境)的操作接口
开放容器标准 (Open Container Initiative) OCI 定义了(runc是参考实现):
- 容器镜像要长啥样,即 ImageSpec。里面的大致规定就是你这个东西需要是一个压缩了的文件夹,文件夹里以 xxx 结构放 xxx 文件;
- 容器要需要能接收哪些指令,这些指令的行为是什么,即 RuntimeSpec。这里面的大致内容就是“容器”要能够执行 “create”,“start”,“stop”,“delete” 这些命令,并且行为要规范。
现在我们可以找到很多符合 OCI 标准或兼容了 CRI 接口的项目,而这些项目就大体构成了整个 Kuberentes 的 Runtime 生态:
- OCI Compatible:runC,Kata(以及它的前身 runV 和 Clear Containers),gVisor。其它比较偏门的还有 Rust 写的 railcar
- CRI Compatible:Docker(借助 dockershim),containerd(借助 CRI-containerd),CRI-O,Frakti,etc
Runtime 方案 Docker
- Kubelet 通过 CRI 接口(gRPC)调用 dockershim,请求创建一个容器。CRI 即容器运行时接口(Container Runtime Interface),这一步中,Kubelet 可以视作一个简单的 CRI Client,而 dockershim 就是接收请求的 Server。目前 dockershim 的代码其实是内嵌在 Kubelet 中的,所以接收调用的凑巧就是 Kubelet 进程;
- dockershim 收到请求后,转化成 Docker Daemon 能听懂的请求,发到 Docker Daemon 上请求创建一个容器;
- Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程——containerd 中了,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器;
- containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让 containerd-shim 去操作容器。这是因为容器进程需要一个父进程来做诸如收集状态,维持 stdin 等 fd 打开等工作。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系);
- 我们知道创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范了,那就是 OCI(Open Container Initiative,开放容器标准)。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器;
- runC 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。
Master 与 Node如何通信
Cluster -> Master
从集群到Master节点的所有通信路径都在apiserver(443端口)中进行。
Node节点应该配置为集群的公共根证书,以便安全地连接到apiserver。
希望连接到apiserver的Pod可以通过service account来实现,以便Kubernetes在实例化时自动将公共根证书和有效的bearer token插入到pod中,kubernetes service (在所有namespaces中)都配置了一个虚拟IP地址,该IP地址由apiserver重定向(通过kube - proxy)到HTTPS。
Master组件通过非加密(未加密或认证)端口与集群apiserver通信。这个端口通常只在Master主机的localhost接口上暴露。
Master -> Cluster
从Master (apiserver)到集群有两个主要的通信路径。
第一是从apiserver到在集群中的每个节点上运行的kubelet进程。
第二是通过apiserver的代理功能从apiserver到任何node、pod或service 。
核心 Addons & Plugins
DNS
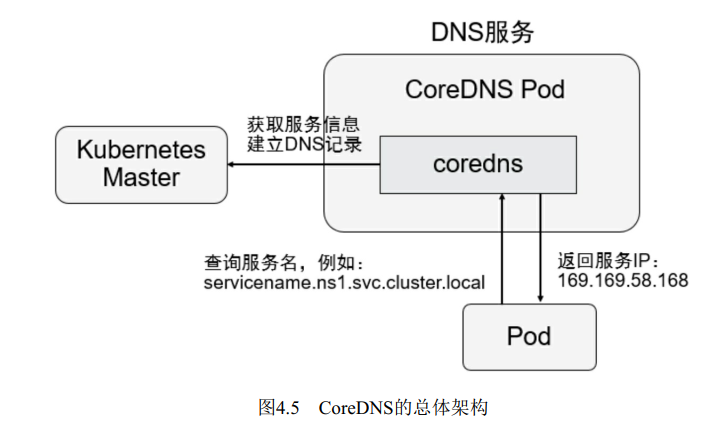
DNS 为集群的服务发现提供的支持,Kubernetes 1.13 开始默认使用 CoreDNS。域名系统(DNS)是一种用于将各种类型的信息(例如IP地址)与易于记忆的名称相关联的系统。 默认情况下,大多数Kubernetes群集会自动配置内部DNS服务,以便为服务发现提供轻量级机制。 内置的服务发现使应用程序更容易在Kubernetes集群上相互查找和通信:
- kube-dns服务监听来自Kubernetes API的服务service和端点endpoint事件,并根据需要更新其DNS记录。 创建,更新或删除Kubernetes服务及其关联的pod时会触发这些事件
- kubelet将每个新Pod的/etc/resolv.conf名称服务器选项设置为kube-dns服务的集群IP,并使用适当的搜索选项以允许使用更短的主机名
- 在容器中运行的应用程序可以将主机名(例如example-service.namespace)解析为正确的群集IP地址
Network Plugin
Kubernetes 多节点环境需要部署网络插件才可以使用,默认情况下使用 flannel 即可。
集群网络创建过程
参考
Kubernetes架构
Kubernetes组件
etcd
Controller Manager
kubelet详细解析
kube-dns与kube-proxy
